policy maps observation to x
observation: 类比于渲染出来的画面 state: 类比于计算机内存状态
if given , is conditionally independent of - > markov property: state: 预测未来的现在状态的信息
goal: given observation, learn policy
behavior clone: using supervised learning
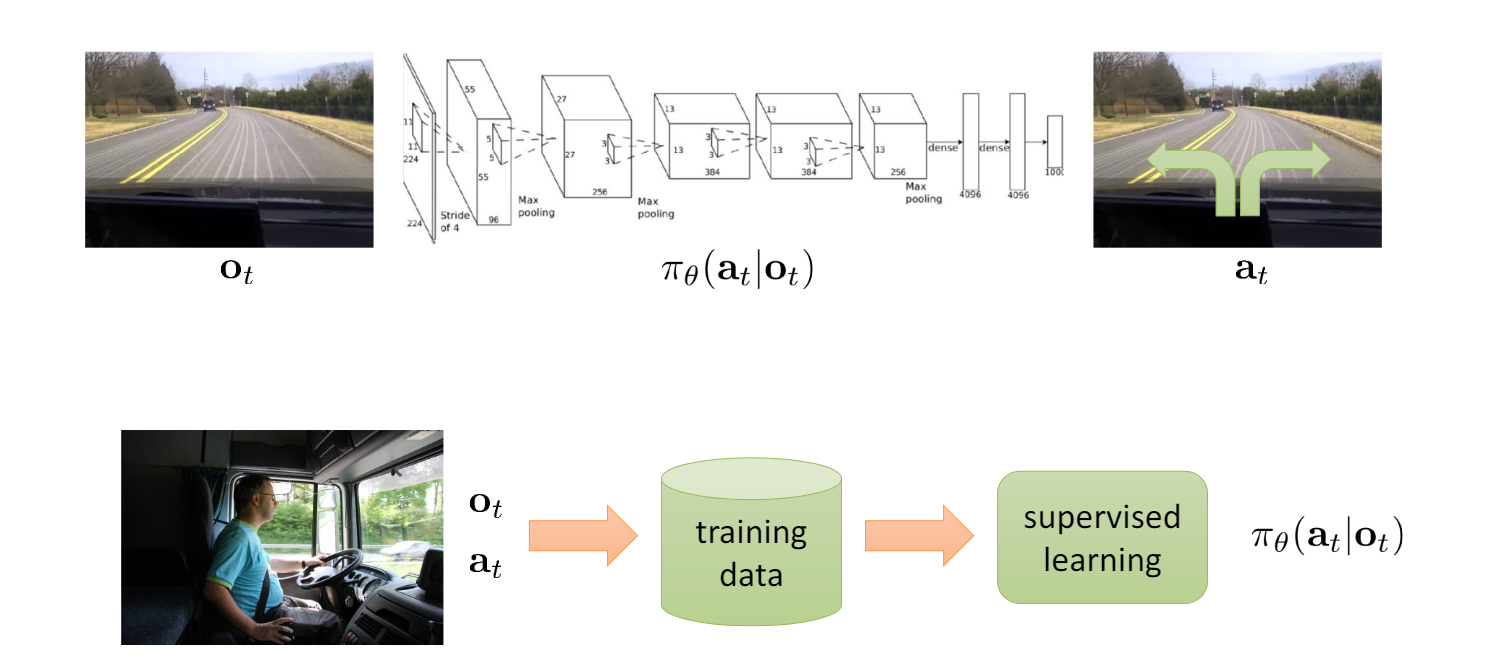
可能会有较大偏差(在传统supervised learning中不会发生 因为是iid) 你在此时刻的选择有一点点改动会影响下一时刻的action
WHY behavior cloning fail?-math