Abs
- 2 ways for pretrained lm to down-stream tasks:
- ElMo: 基于特征 对每一个下游任务构造一个跟这个任务相关的神经网络。预训练好的表示(额外的特征)和预训练一起输入,作为特征表达
- GPT: fine-tuning 下游,权重微调 二者单向
- 贡献
- 双向
- 微调
related
unsupervised fine-tuning → GPT
unlabeled 句子对→训练好bert模型,对每一个下游任务训练,权重初始化来源于训练好的模型。labeled数据
Method
- 可学习参数
- 输入是字典大小 输出(hidden size) H
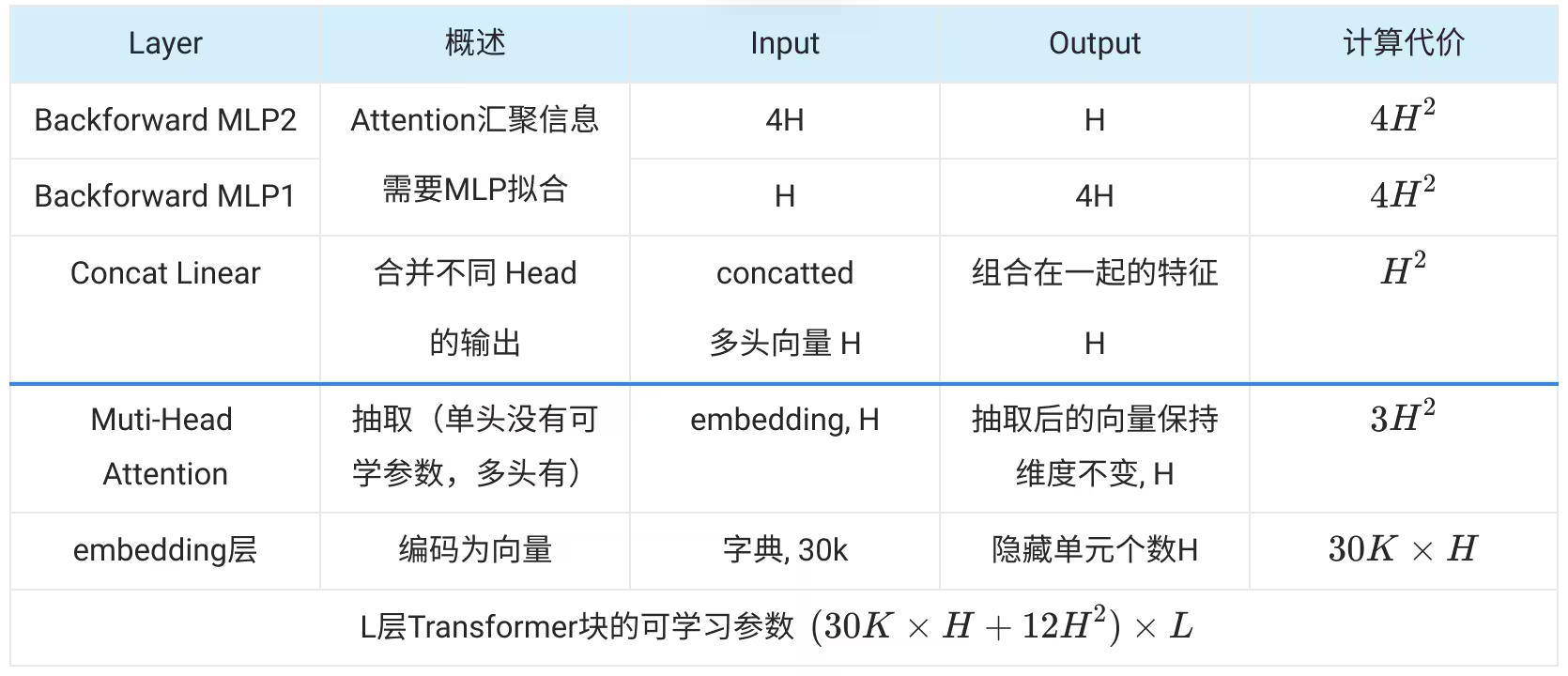
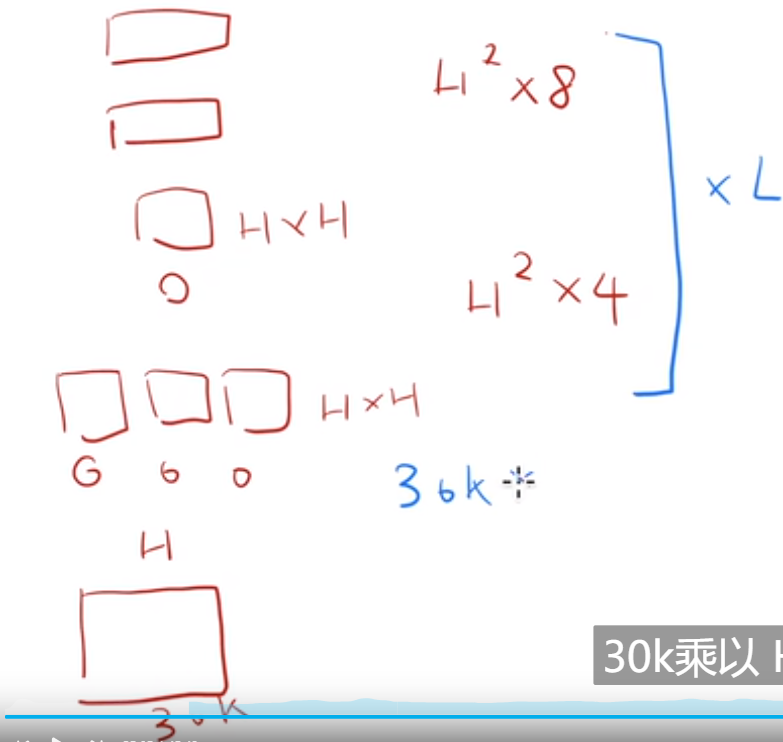 输入30K,embedding后是H,self-attention 头(H*(H/h)*3 一共有h个头
输入30K,embedding后是H,self-attention 头(H*(H/h)*3 一共有h个头
- 输入是字典大小 输出(hidden size) H
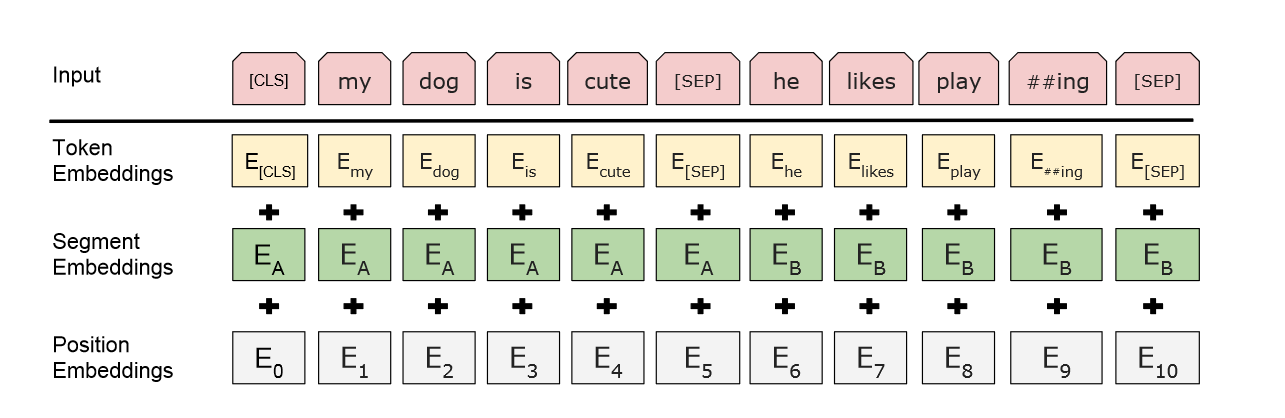
- embedding
- 片段 子序列
- CLS 开头 表示句子的信息
- 区分每个句子:
- 在每个句子后面放一个词SEP
- 学一个嵌入层 学习是第一个句子还是第二个
预训练和微调不一样
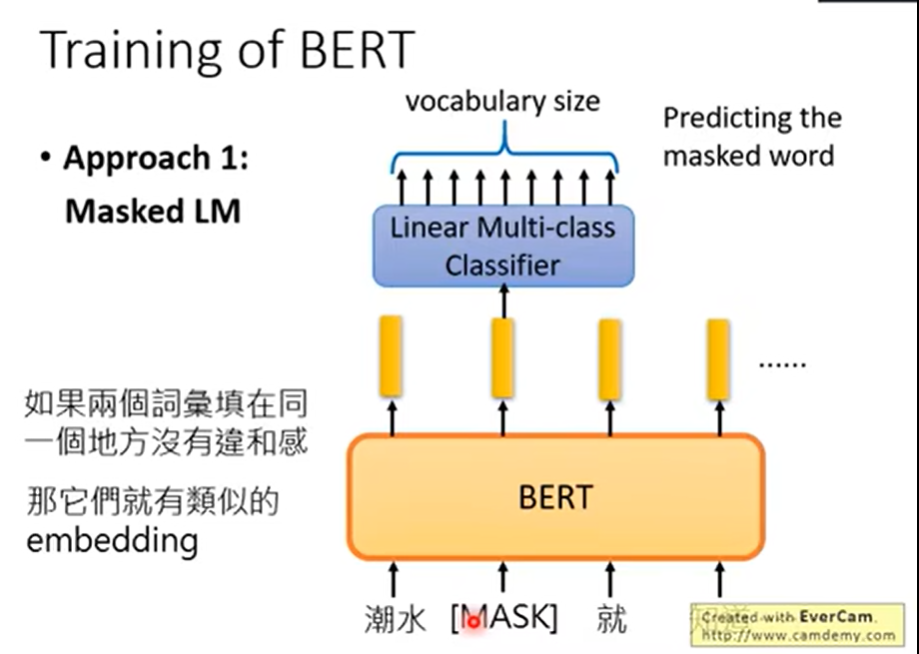
1.train 替换为mask 2. 不能做seq2seq 的生成式(机器翻译,文本摘要)做分类很好做
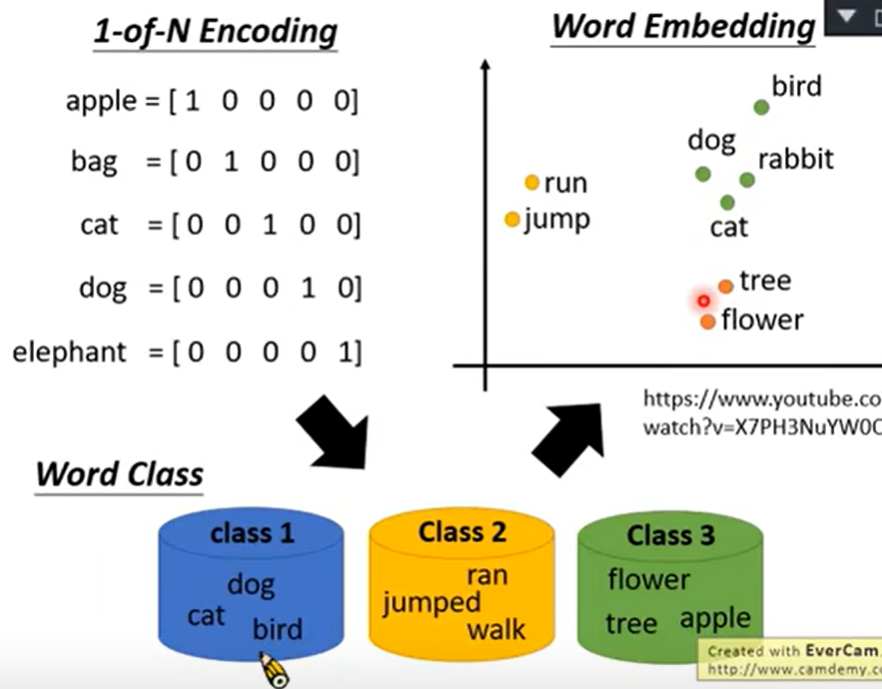 即使不同token 有相同type,每一个token有一个embedding→ contextualized word embedding
即使不同token 有相同type,每一个token有一个embedding→ contextualized word embedding

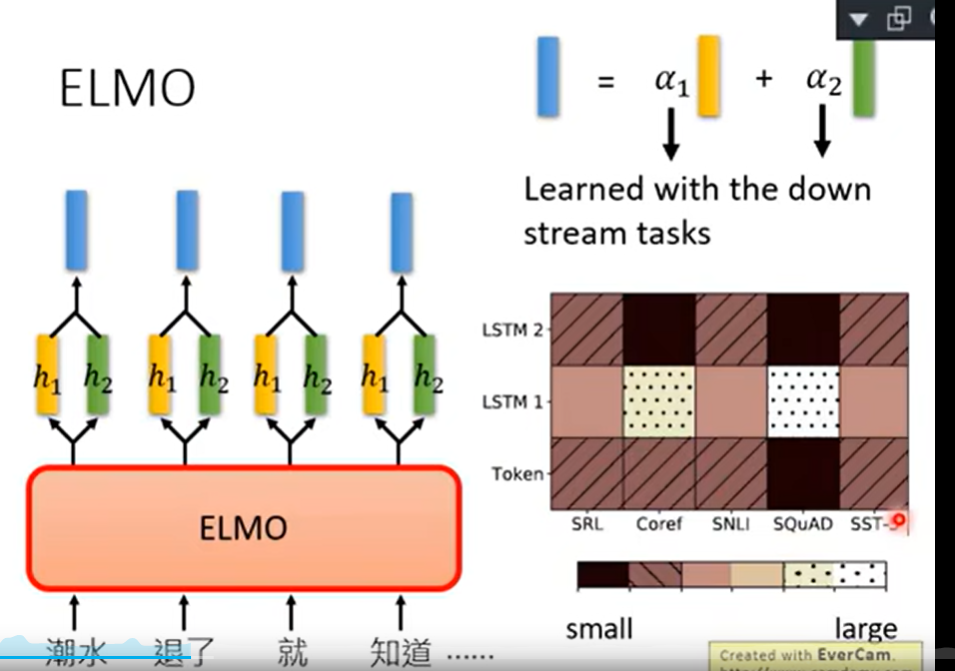
ELMO
预测下一个token →contextualized word embedding
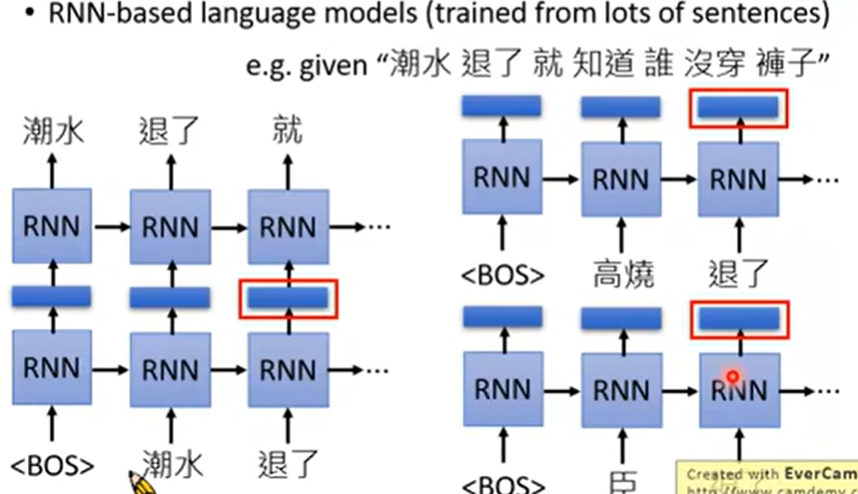
训练一个反向
根据不同任务学出不同的weight
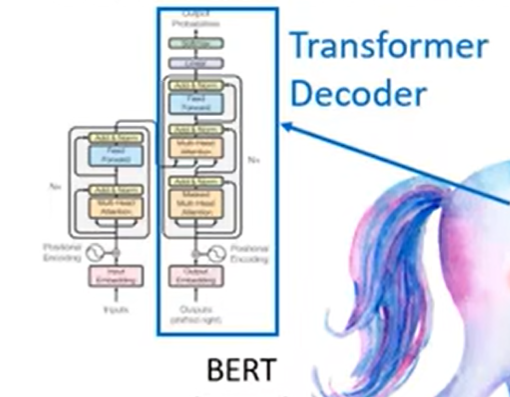
Bert
作为character输入 更合适(字典大小固定
cls经过classifier之后 输出两个句子是否接在一起(CLS看到整个句子的信息)

同时使用qpproach 1 & 2
Linear从头学,Bert微调:
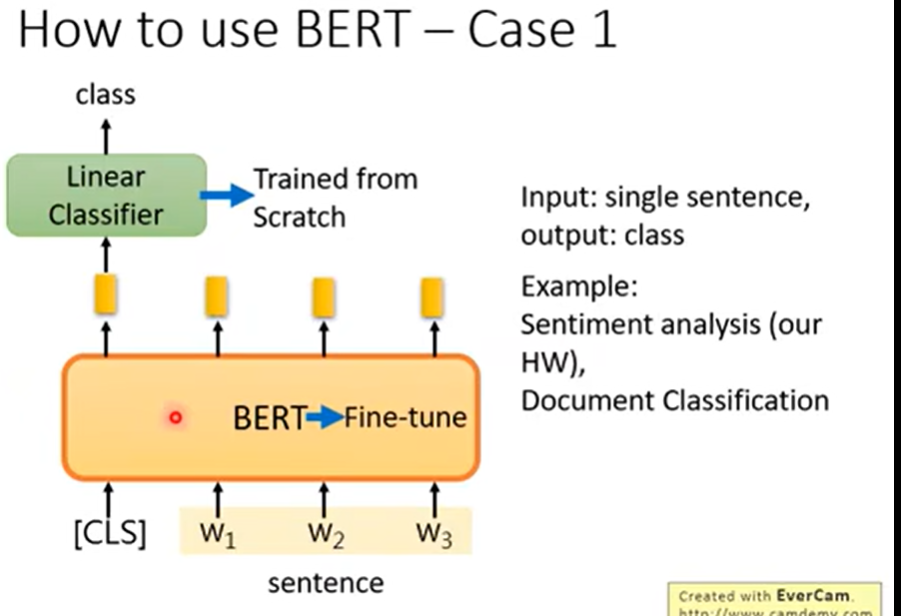
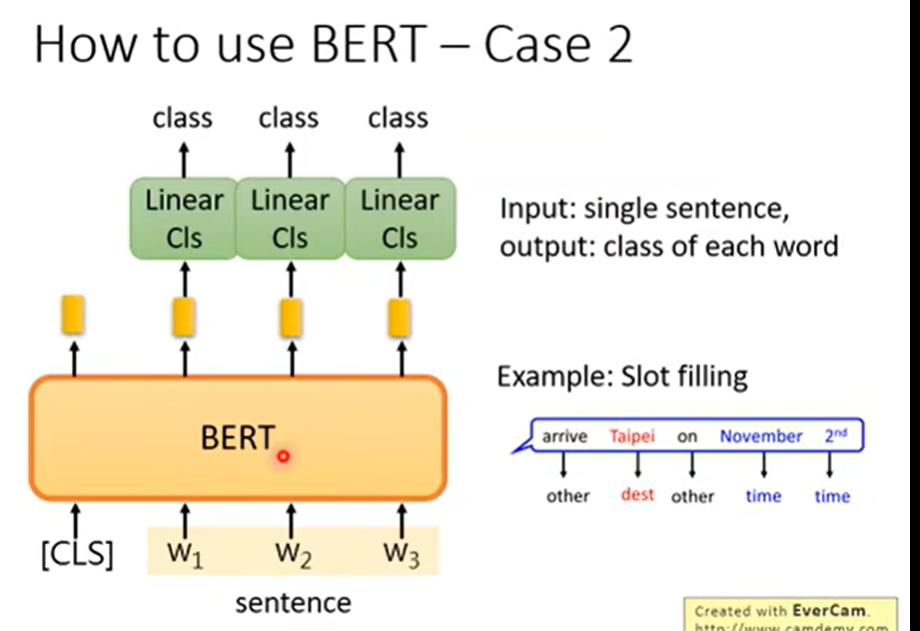
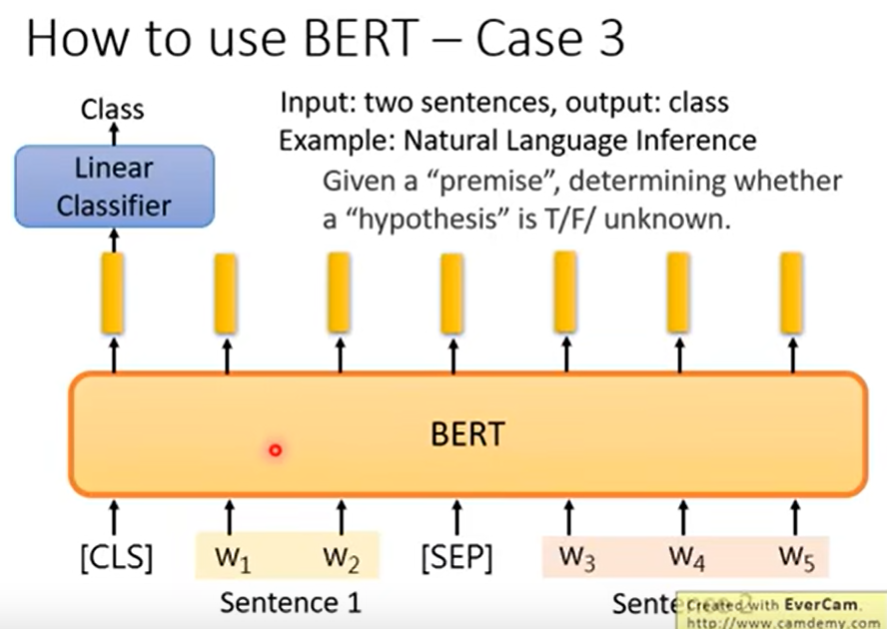 QA: 输出答案在文章中的位置
QA: 输出答案在文章中的位置

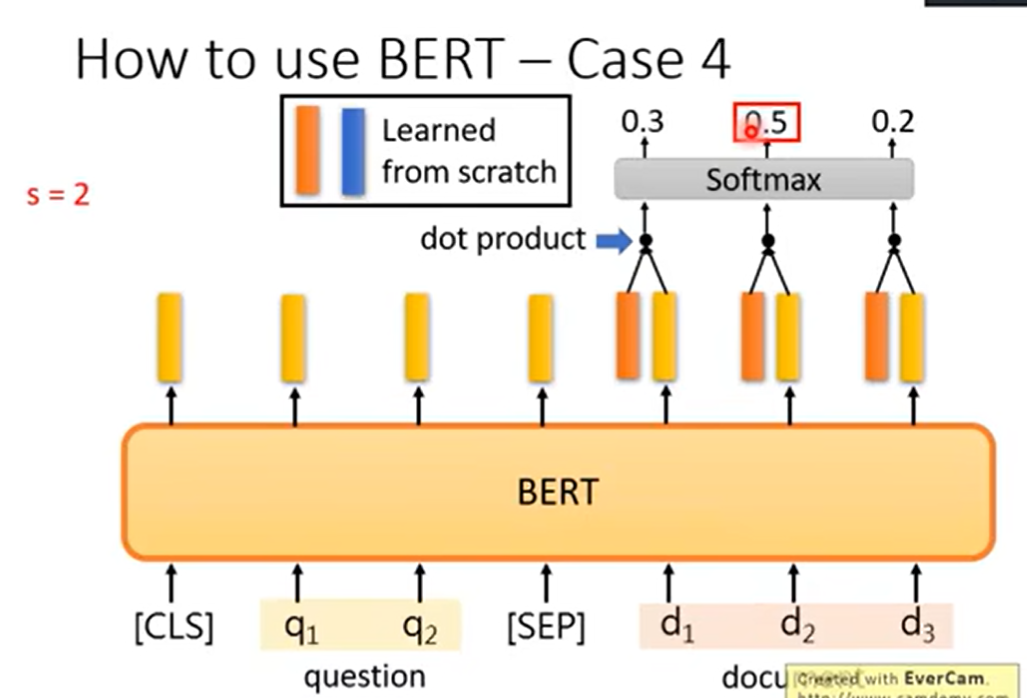 output 矛盾→无解
output 矛盾→无解
GPT