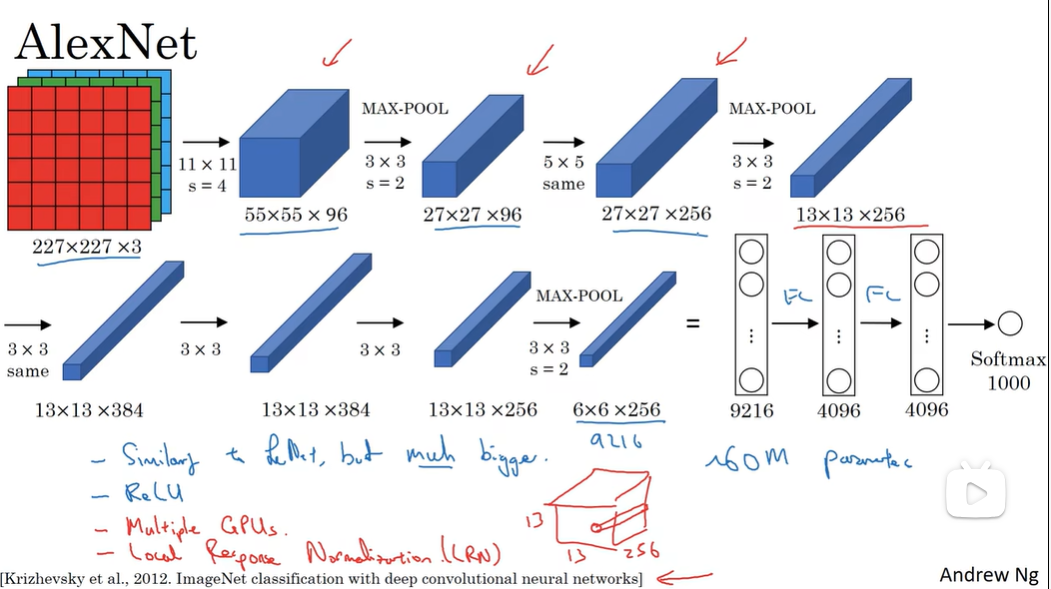
经典网络
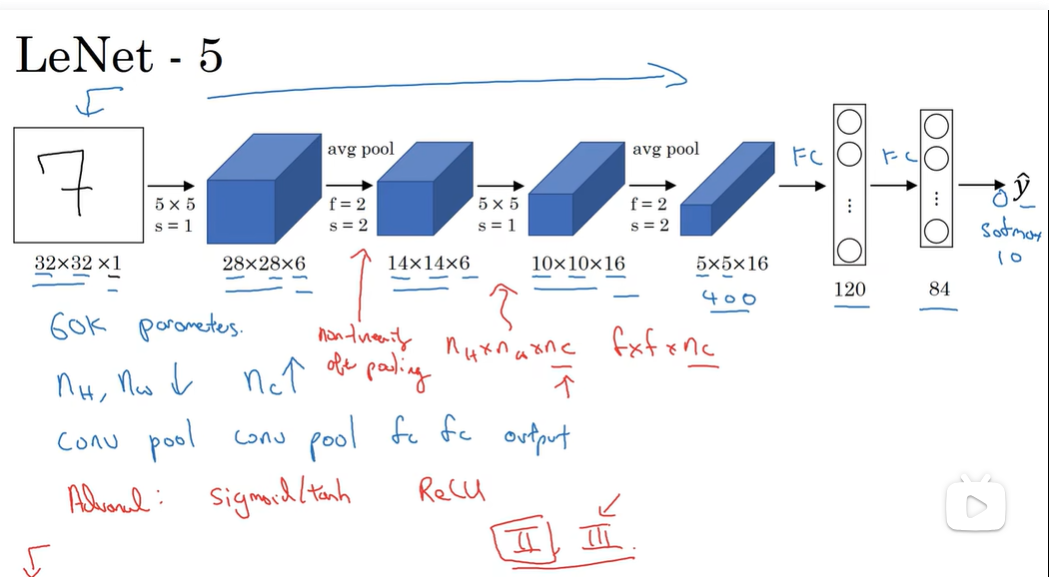
Lenet-5
VGG
简化了nn结构
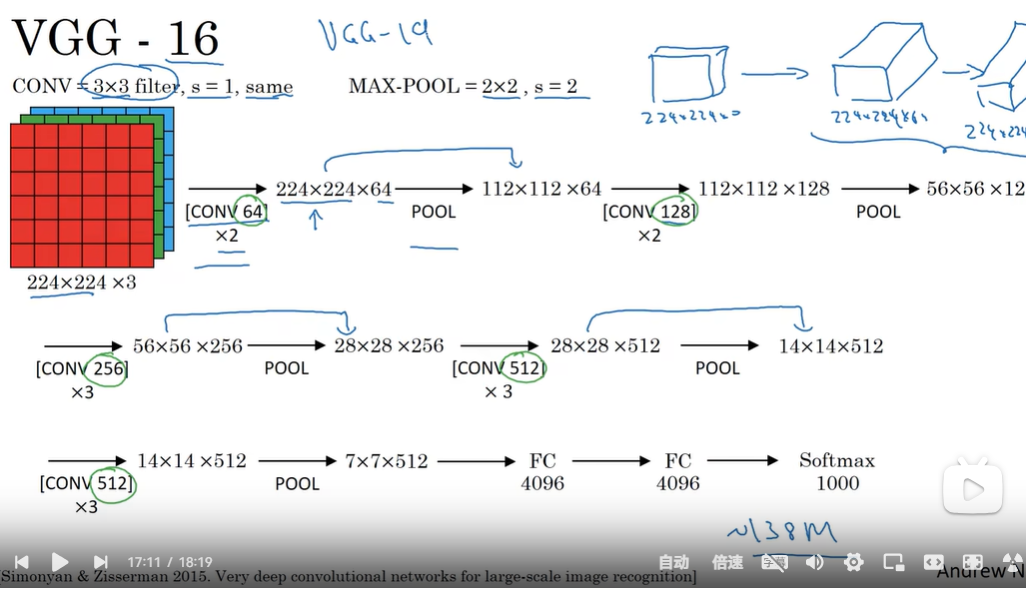 高 宽逐渐减小,通道数增加
高 宽逐渐减小,通道数增加
残差网络
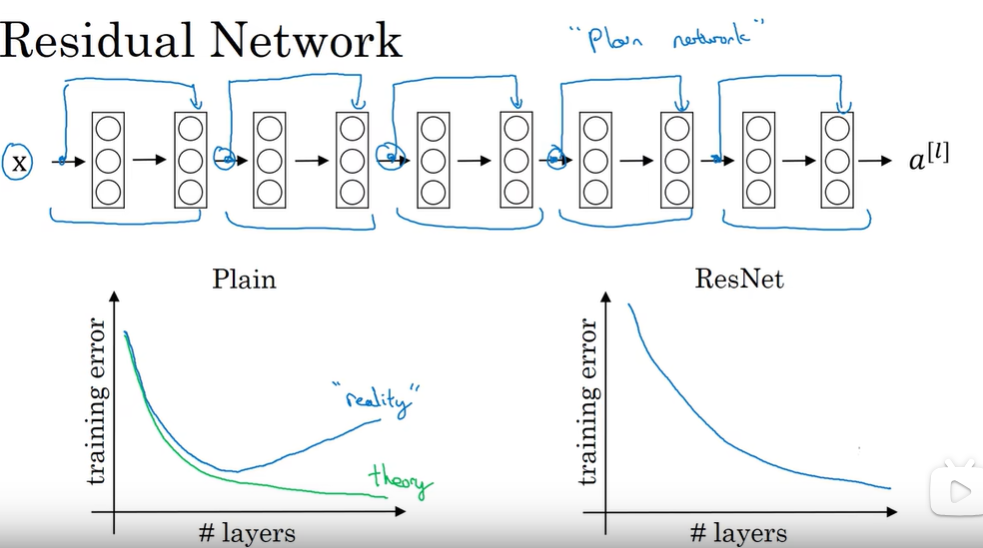
深的神经网络很难训练因为梯度消失和梯度爆炸
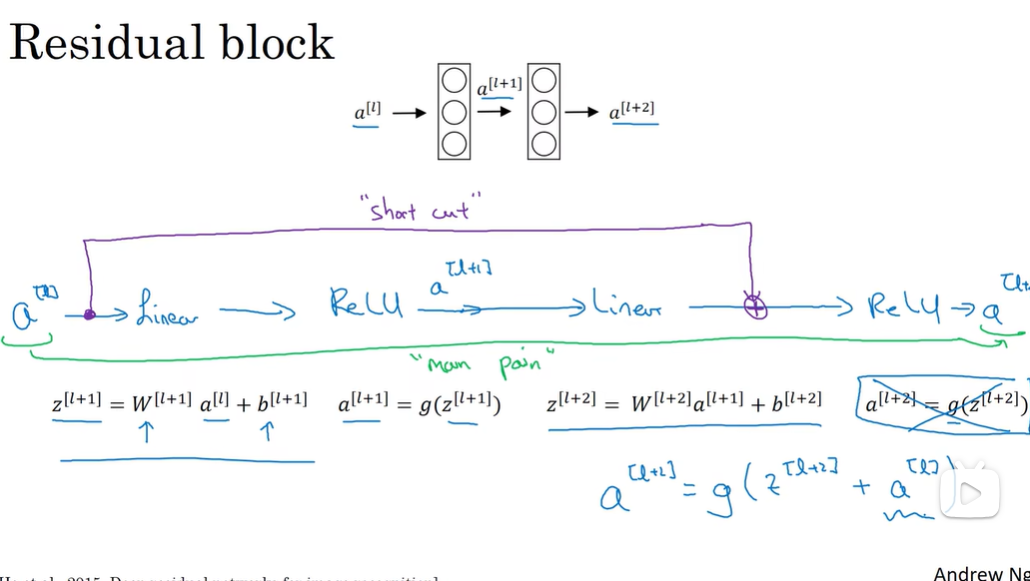
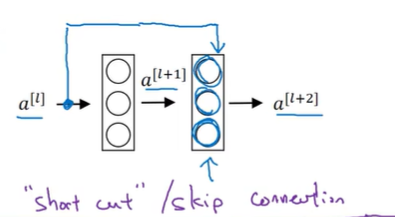 未加残差的是plain nn:
未加残差的是plain nn:
 如果使用l2正则(权重衰减),前面的w会不断缩小,假设缩小到0,则最后还是 ,这不影响网络的学习效率,因为他是一个恒等式。
如果使用l2正则(权重衰减),前面的w会不断缩小,假设缩小到0,则最后还是 ,这不影响网络的学习效率,因为他是一个恒等式。
注意: 和 需要同一个维度,而Resnet中用了很多相同的卷积,所以维度相同。
如果不相同,也可以用一个矩阵,
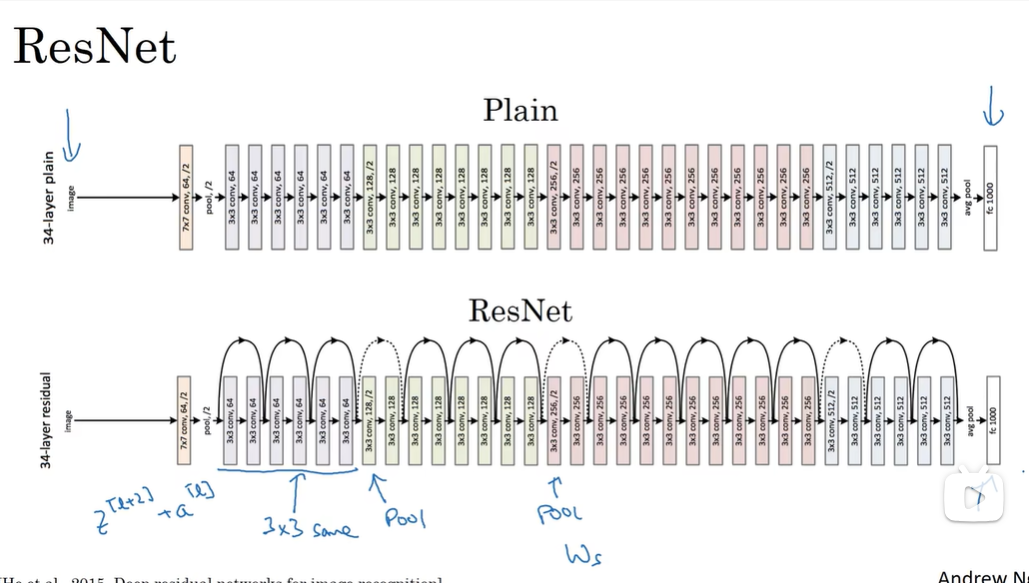 中间的虚线是有pooling,维度不同skip时用矩阵。
(他解决的一个问题就是当时深度学习网络随着网络层数加深而产生的退化问题。
中间的虚线是有pooling,维度不同skip时用矩阵。
(他解决的一个问题就是当时深度学习网络随着网络层数加深而产生的退化问题。
解决方法就是恒等映射,该恒等映射保证了相比于浅层网络钱,深层网络至少可以得到一个不差于浅层网络的结果。我在直观上认为,层数越多的网络他的解空间就会越多,加上这个恒等映射可能就是对网络在探索解空间时的一个约束,这个约束保证网络参数不会朝着一个奇怪的方向前进)
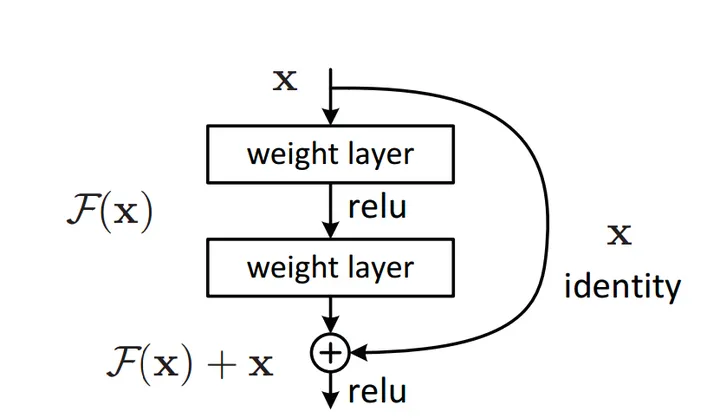
 (残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器…)
(残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器…)
1x1网络(network in network)
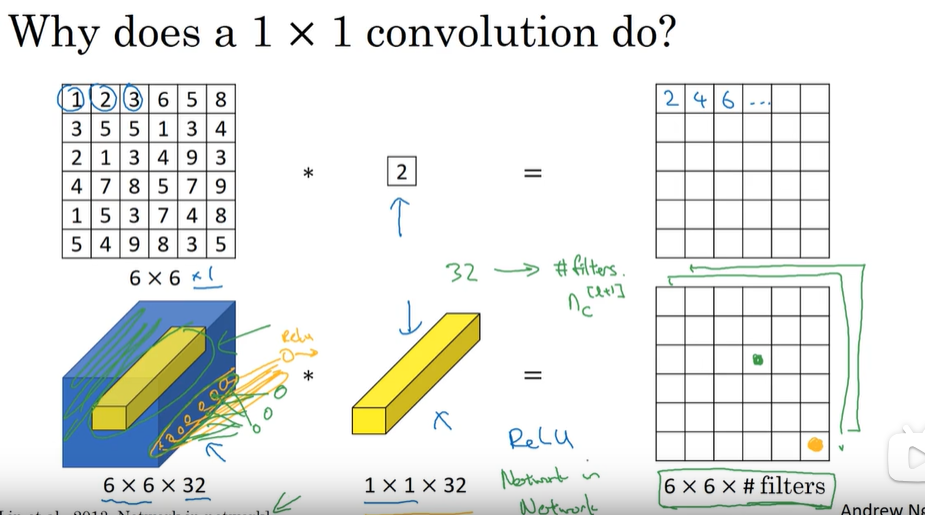 对于32个通道(1x1卷积后加入relu),相当于对他们进行了一次fc → 减小通道数,
对于32个通道(1x1卷积后加入relu),相当于对他们进行了一次fc → 减小通道数,
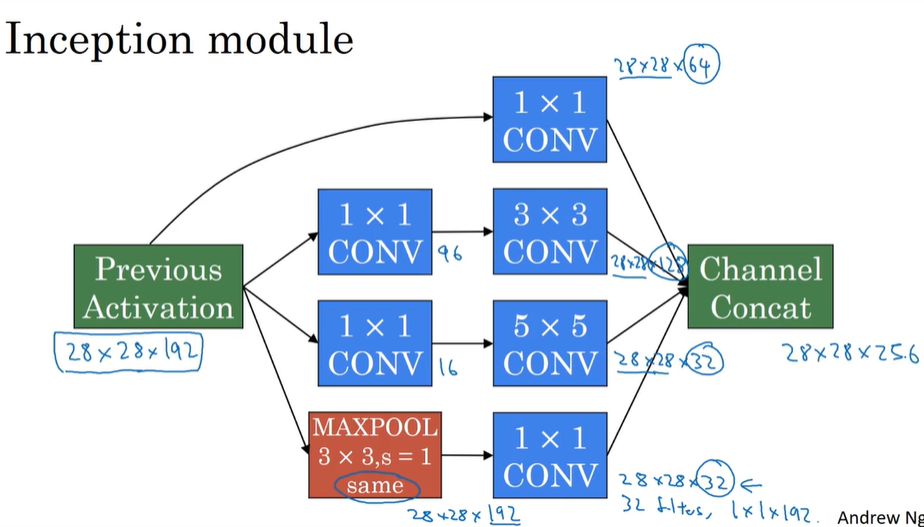
Inception
代替人工确定卷积层中过滤器类型,确定是否创建卷积层或池化层
不需要确定是什么层,将这些输出连接起来让网络自己学习它需要什么参数
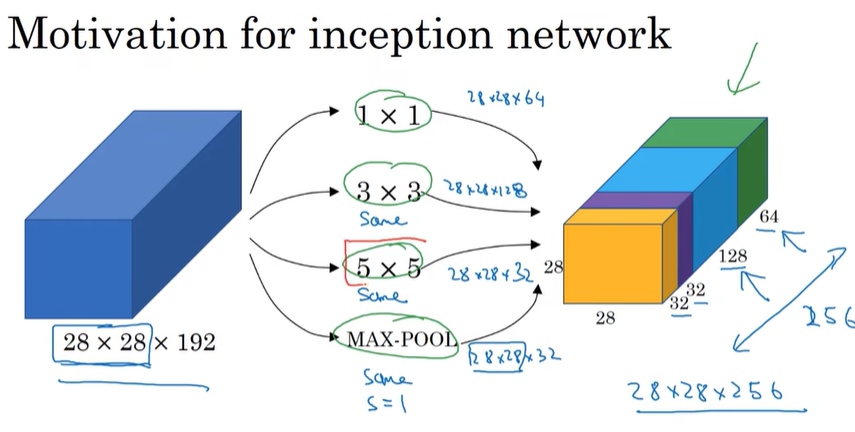 padding类型是same,maxpooling 需要是padding
padding类型是same,maxpooling 需要是padding
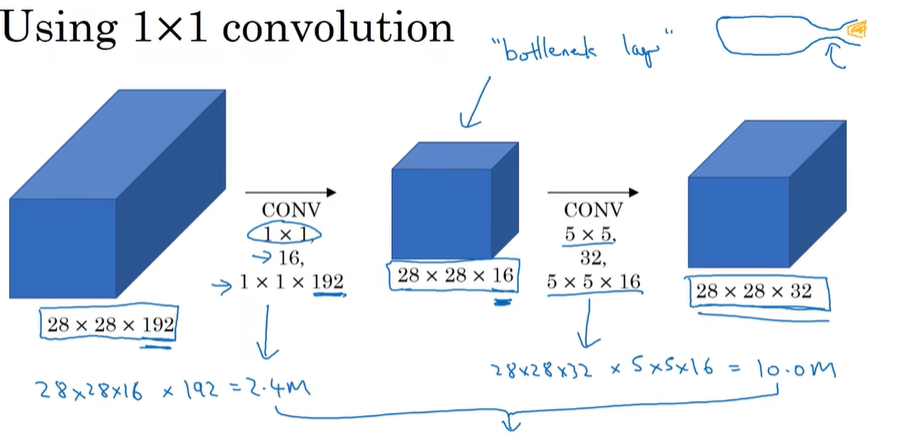
计算成本:
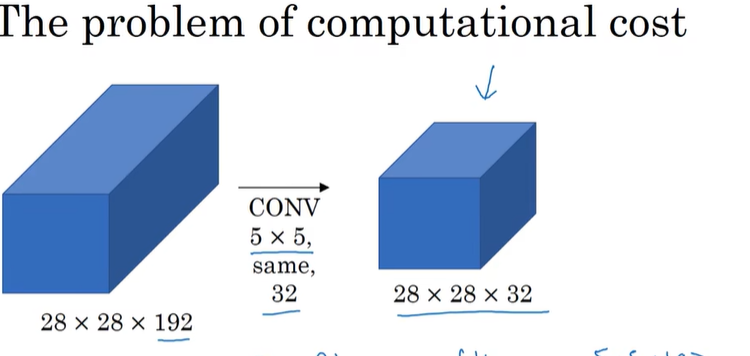 每个filter是5x5x192, 计算28x28x32需要每个进行5x5x192次运算 →计算成本很高昂→ 用1x1卷积减少运算量:
每个filter是5x5x192, 计算28x28x32需要每个进行5x5x192次运算 →计算成本很高昂→ 用1x1卷积减少运算量:
先1x1卷积减小信道数,然后进行5x5卷积。中间的称为bottleneck layer:
最后池化层进行1x1卷积,32 filters,避免池化层最终信道数占比过多
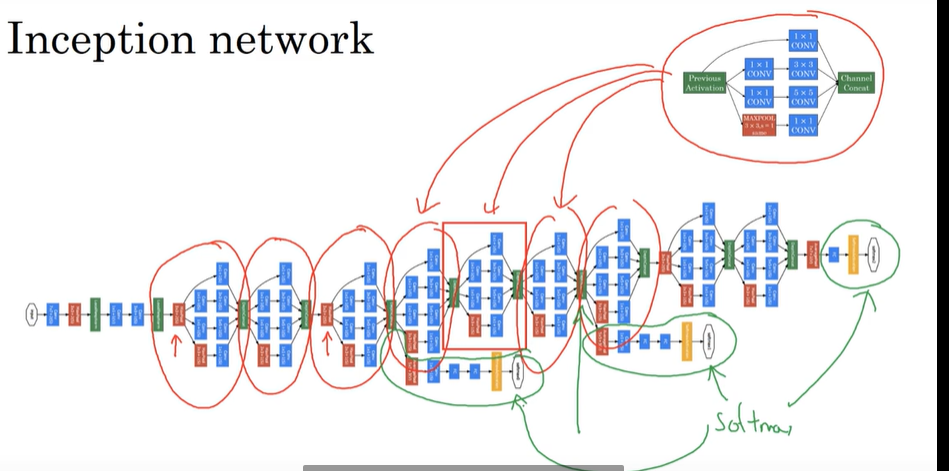
中间的隐藏层也链接有softmax: 可以预测
迁移学习
更大数据集:训练更大一点的网络
数据扩充
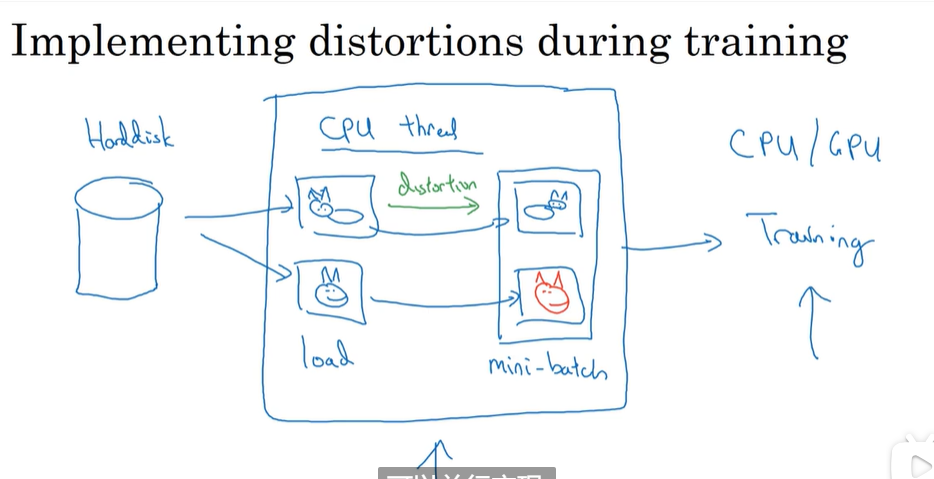
用一个线程加载数据,另一个线程训练,二者可以并行