归纳偏置(inductive bias): y
pre
- CNNs不解决:
- 之前 小的patch 2x2
1.
 2.
2. 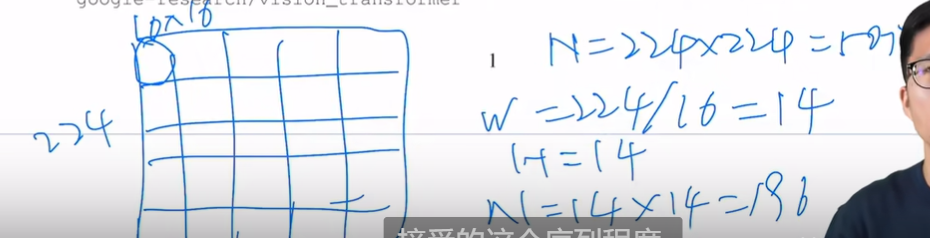 196个元素 supervised
3.若没有strong regularization 会比同等大小resnet少acc,因为 Transformer 缺少inductive bias(就是一种先验的假设)
196个元素 supervised
3.若没有strong regularization 会比同等大小resnet少acc,因为 Transformer 缺少inductive bias(就是一种先验的假设)
inductive bias:
- location 相邻区域有相邻特征
- traslation equivalence(平移等变性)
- f(g(x))=g(f(x)) 无论先做平移还是卷积 输出是一样的 网络有这个归纳偏置有了先验信息,而transfomer没有这样的先验信息 所以他对视觉的感知全都需要自己从数据中学(???)
结论: 有足够数据预训练,transformer比inductive bias要好,在下游任务上有很好的迁移学习效果
Bert:完形填空 LM:一个句子预测下一个词是什么
Method
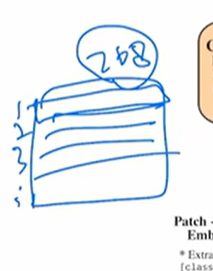
0 :cls
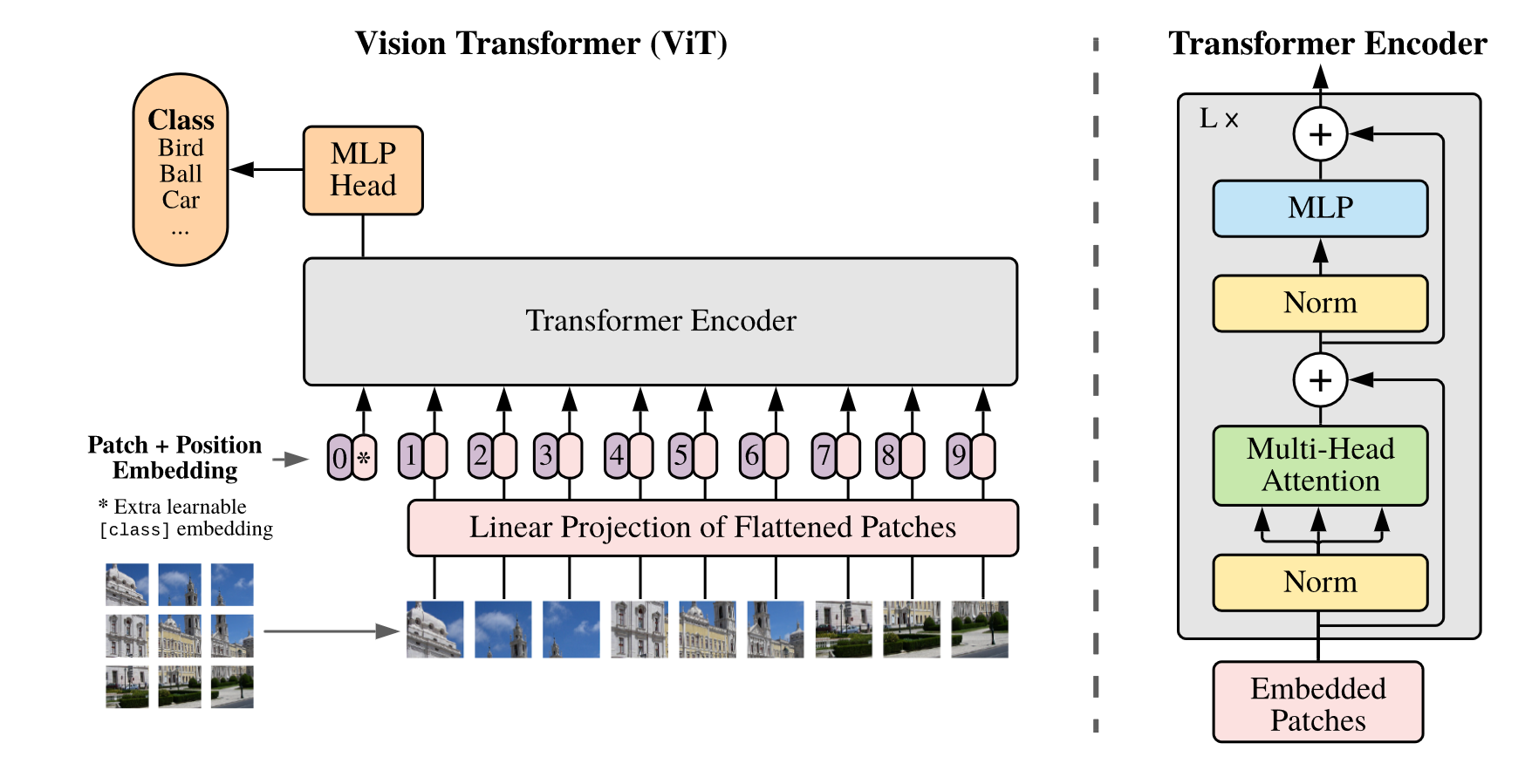 本身 : 224x224x3
14x14个patch 每个大小为16,变为了196x768维度(768=16x16x3 3个通道)
linear projection: 768x768
最后序列长度 (196+1) x 768 ( 1是cls token)
位置信息如何加: 每一行是一个1x768向量,这个作为编码(像素)直接sum到原来序列 最后还是197x768
本身 : 224x224x3
14x14个patch 每个大小为16,变为了196x768维度(768=16x16x3 3个通道)
linear projection: 768x768
最后序列长度 (196+1) x 768 ( 1是cls token)
位置信息如何加: 每一行是一个1x768向量,这个作为编码(像素)直接sum到原来序列 最后还是197x768
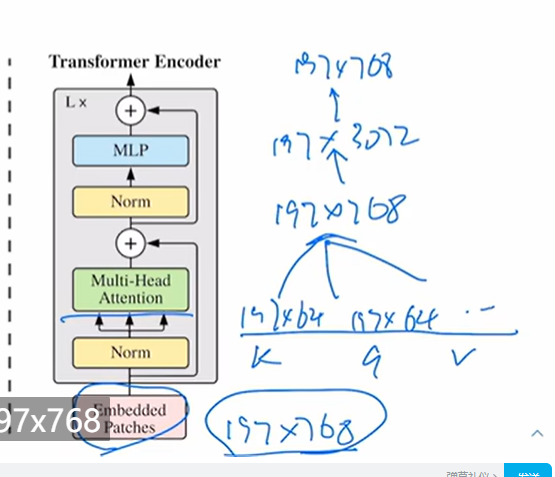
- 从头到尾序列长度都是768(原先是基于patch size 16算出的(14x14x3)),如果patch size改变则序列长度改变,通过添加一个linear projection还回到768和transformer维度匹配上
- 原先res50中:
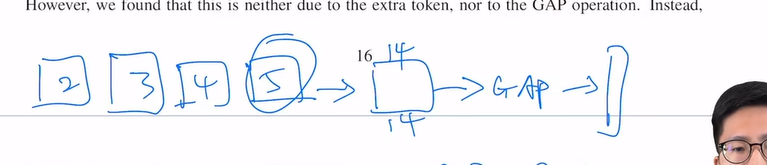
- 也能在vit最后输出上做GAP
其他:
- 如果改变patch size,那么序列长度变化,原先预训练的位置信息不能用→插值
- 比传统卷积训练 便宜
- 尝试自监督训练: masked patch prediction (比有监督的预训练要差)
之后:Contrastive方式训练ViT:Mocov3 DINO
消融实验:
- figure4: 因为transformer缺少那些先验和约束方法(weight decay , label smoothing那些),导致小数据上的vision transformer容易过拟合(如何ViT做小样本学习??)
- 为什么在更大数据集上 混合不如ViT,(为什么卷积抽取出来的特征没有帮助Transformer更好的学习) 怎么预处理图像,怎么做tockenization’
Conclusion
- 尝试自监督
- 更大