2.2
- logistic
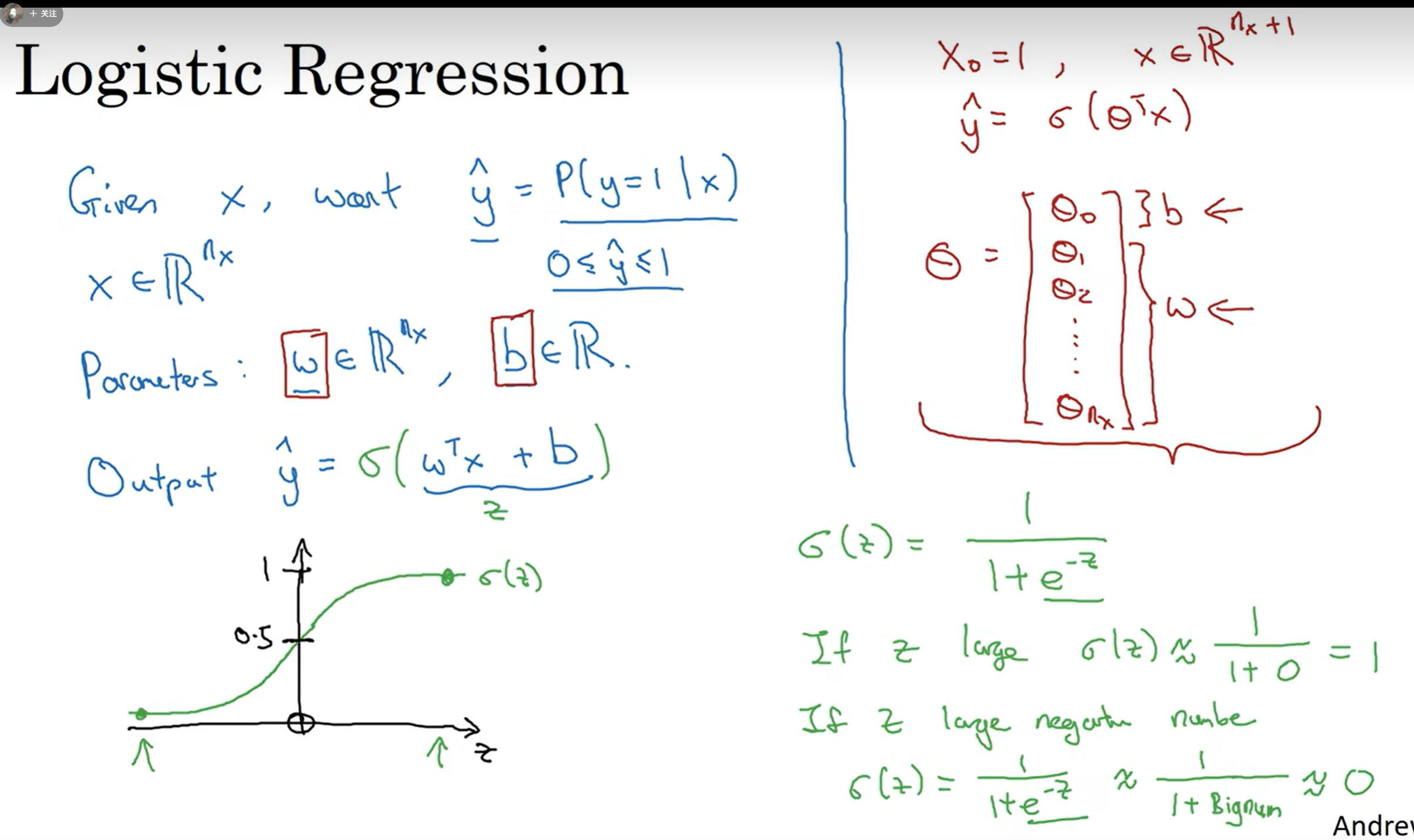
- loss
- i-th sample

- 不用squared error,会有优化问题,变成non-convex,会有很多local-minima
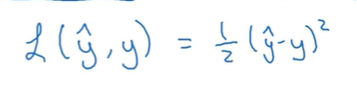
- loss→single training example cost function→cost of parameters
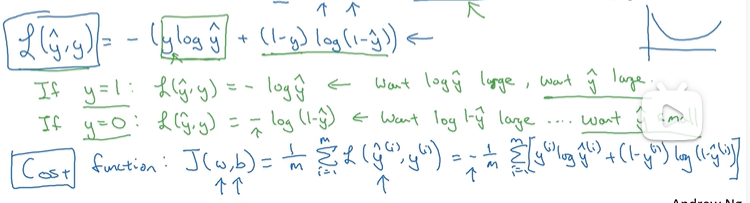
- i-th sample
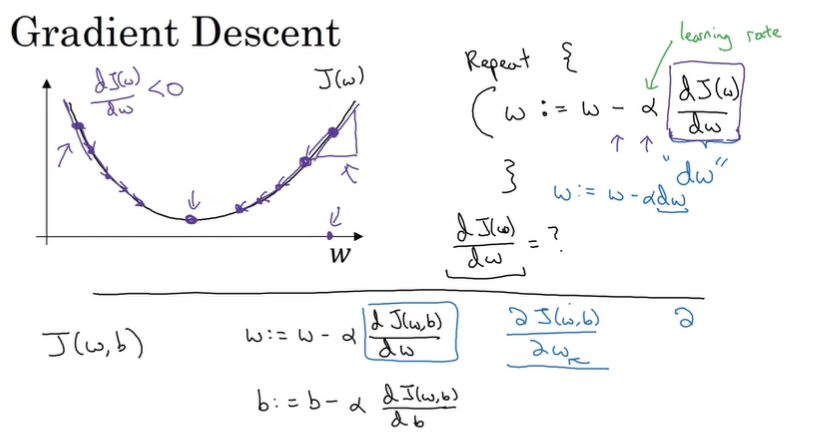
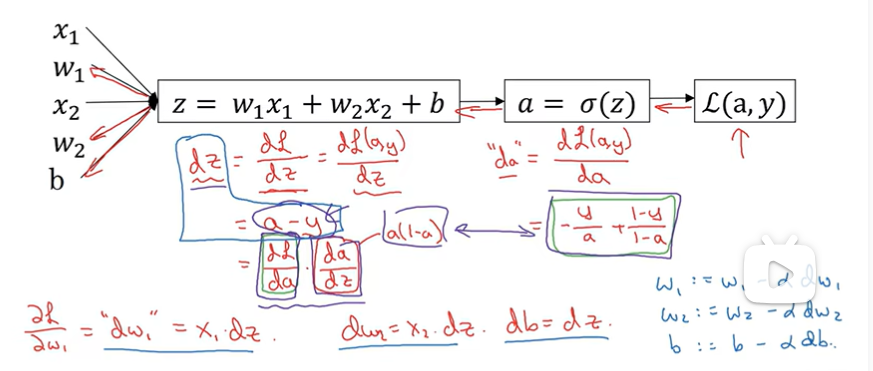
2.4 Gradient
2.7 computational graph
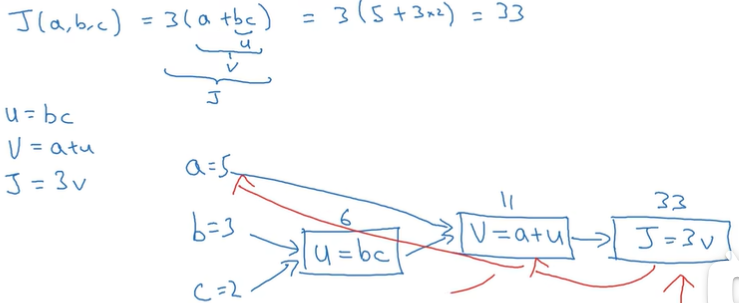
2.9 logistic for gradient
- dz只是coding中变量名
2.10 m samples
- naive:
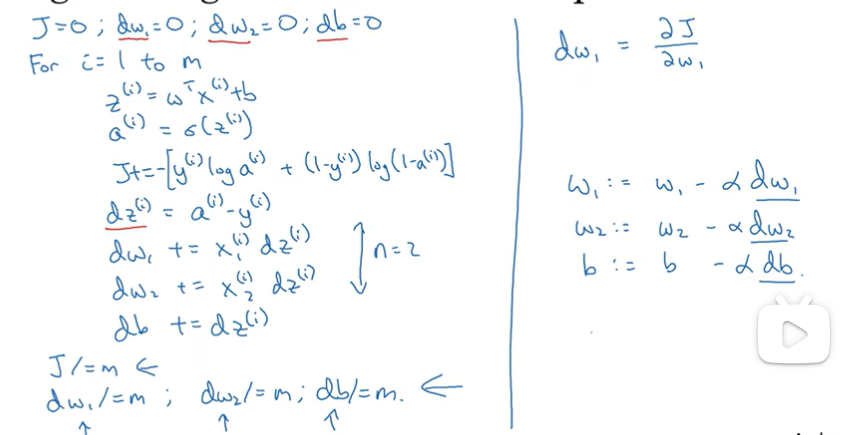 缺点:
缺点:
- 2 for-loop : 1)samples 2) features
2.11 Vectorization
z=np.dot(z,x)+b
 广播机制:
广播机制:
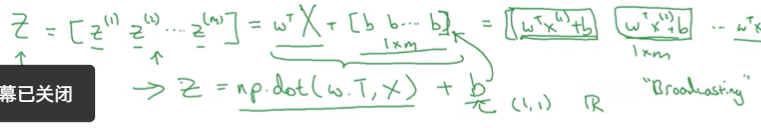
for logistic:

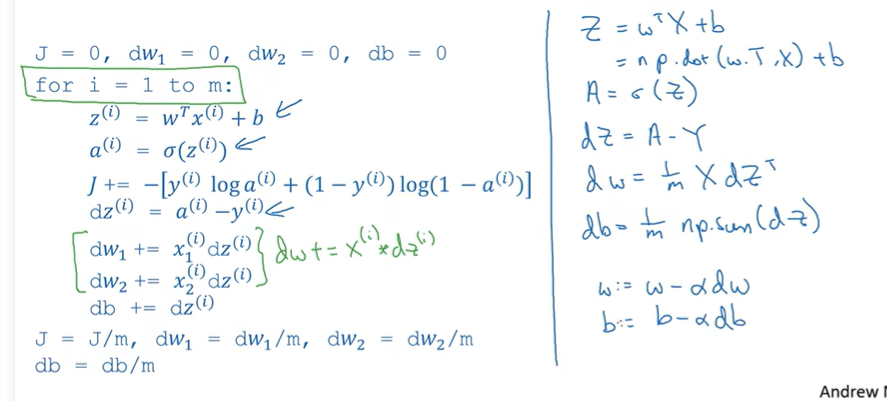
2.15 Broadcasting

 对行列同样有效
对行列同样有效
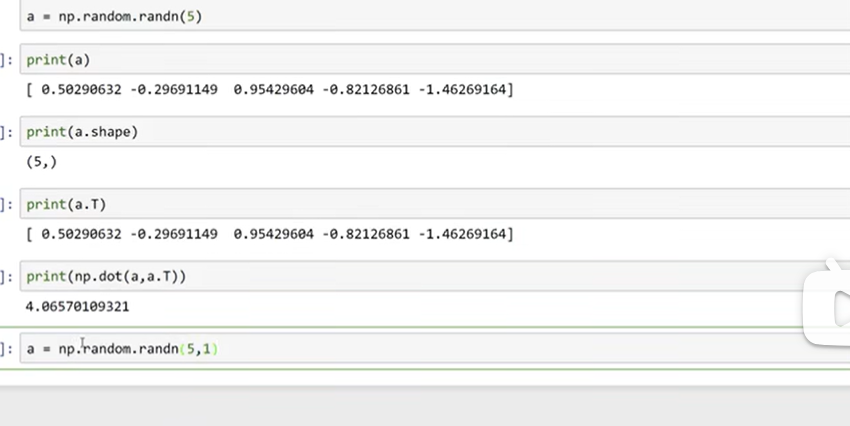
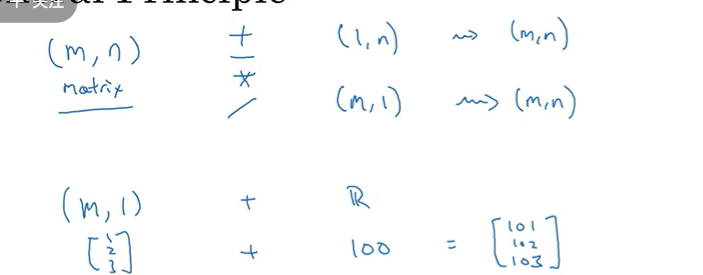 trick:
trick:
- 初始化nx1向量而不是秩为1的矩阵
- 上面那样a外积本来应该是矩阵确是数字

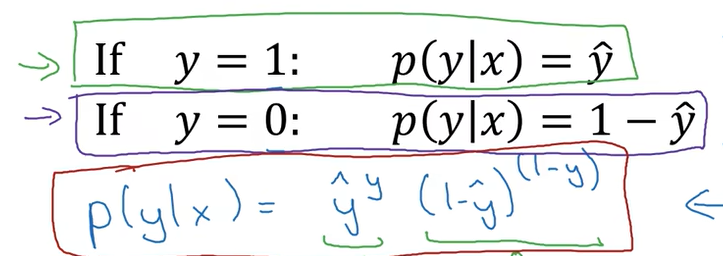
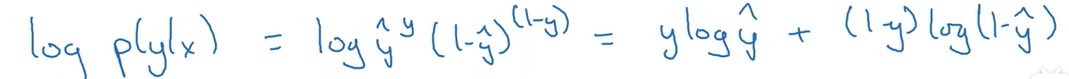 最大似然估计:iid
最大似然估计:iid

- 上面那样a外积本来应该是矩阵确是数字