错误分析
![[Pasted image 20240122113107.png]]
1.如果被错误分类的100里面只有5张是狗,即使解决了狗的错误,错路率只下降5%,这个方向可能没有价值
![[Pasted image 20240122113506.png]]
表格可以筛选高优先级的任务
清除标注错误的数据
-
training set里面随机错误(random error)很robust
-
但对systemetic error不robust(一直标注为错的)

划分数据集
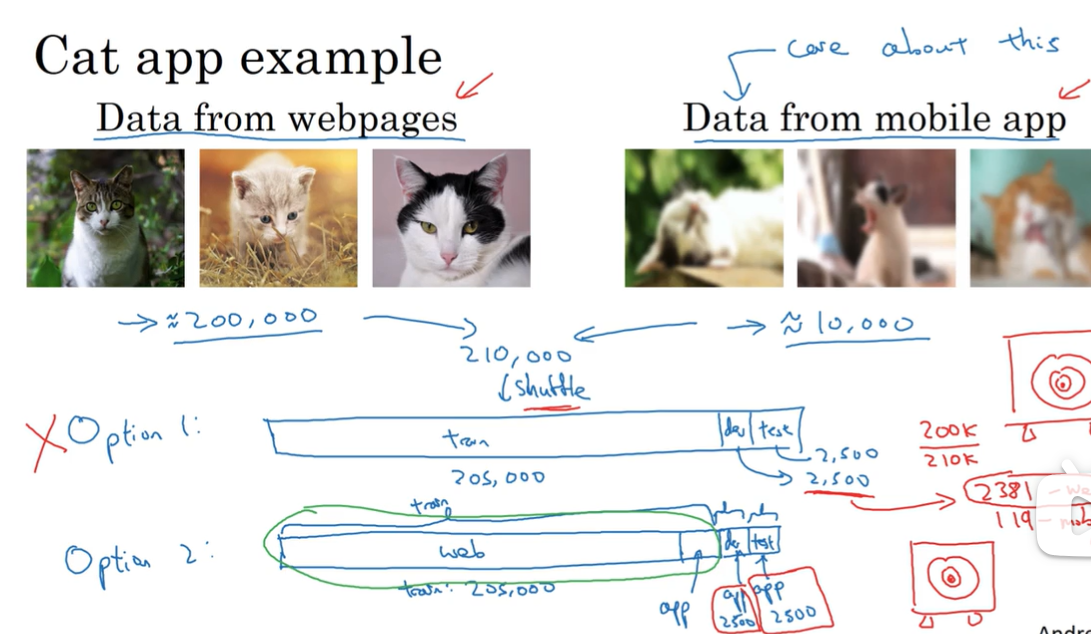
web:200,000 app:5000真正关心的是app上的数据分布,所以最好选第二种,dev test全部是app的数据(可以在training set中加入一部分app的数据),更有助于长久的性能优化
不匹配数据划分的偏差和方差
 有两种可能:
有两种可能:
- training 和dev来自同一分布,model没见过dev数据 → 泛化性差,variance 问题
- training和dev 来自不同分布
来自不同分布的解决:
随机shuffletraining数据集,划分一部分作为training-dev set,在training-dev set上不作训练。这样training set 和traing dev set来自同一分布,在上面验证可以观察是否有泛化性的问题
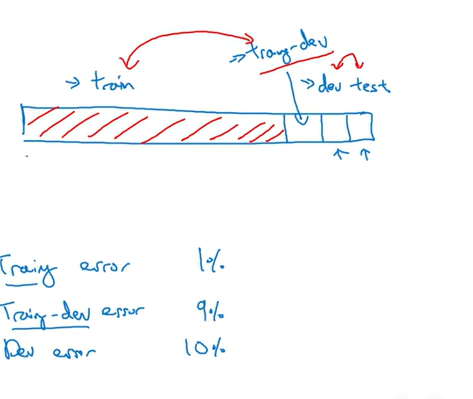 如上图,有variance 问题
如上图,有variance 问题
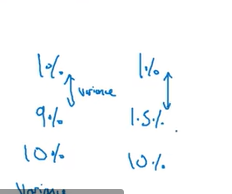 如上图,有data mismatch问题
如上图,有data mismatch问题
 如果dev error和test error差距过大说明model可能在dev set上过拟合了(bigger dev set
如果dev error和test error差距过大说明model可能在dev set上过拟合了(bigger dev set
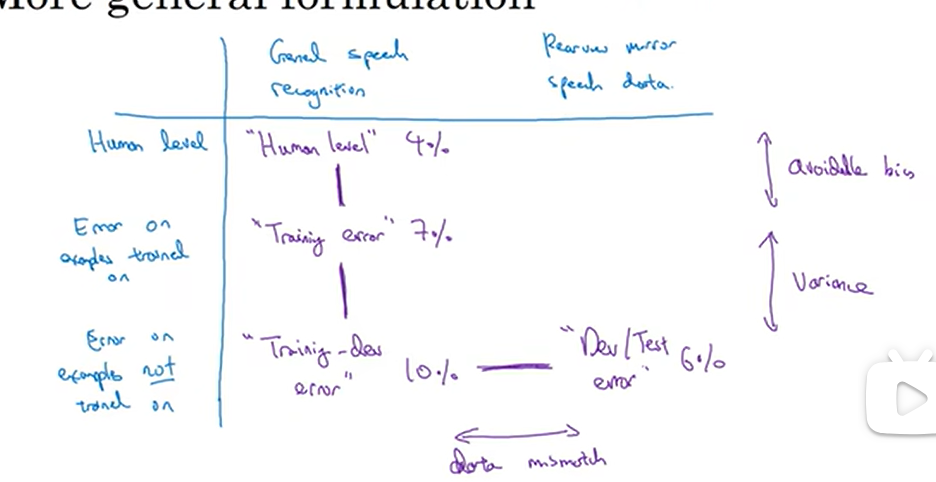
解决数据不匹配(mismatch)
让训练数据更接近dev set:人工合成数据 问题:从所有可能的空间只选了一小部分去模拟数据,可能对这一小部分数据过拟合
迁移学习
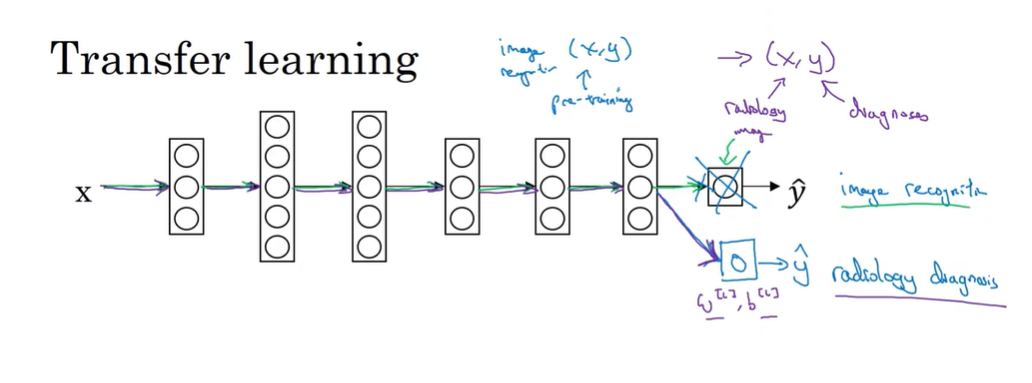 将学习到的知识应用在其他任务上。去除最后一层权重重新训练,(或数据足够多也可以重新训练整个网络。如果重新训练所有参数,则网络初期训练成为预训练,之后更新所有权重在别的任务上称为微调)
why helpful:很多low-level的特征比如边缘检测,曲线检测,positive objects检测,能从很大的图像识别数据库中获得这些能力。(适用于:当任务A的数据比任务B多得多时,迁移学习意义更大.因为希望提高B的性能,任务A里单个样本的价值没有比任务B单个样本价值大
将学习到的知识应用在其他任务上。去除最后一层权重重新训练,(或数据足够多也可以重新训练整个网络。如果重新训练所有参数,则网络初期训练成为预训练,之后更新所有权重在别的任务上称为微调)
why helpful:很多low-level的特征比如边缘检测,曲线检测,positive objects检测,能从很大的图像识别数据库中获得这些能力。(适用于:当任务A的数据比任务B多得多时,迁移学习意义更大.因为希望提高B的性能,任务A里单个样本的价值没有比任务B单个样本价值大

多任务学习(Multi-task learning)
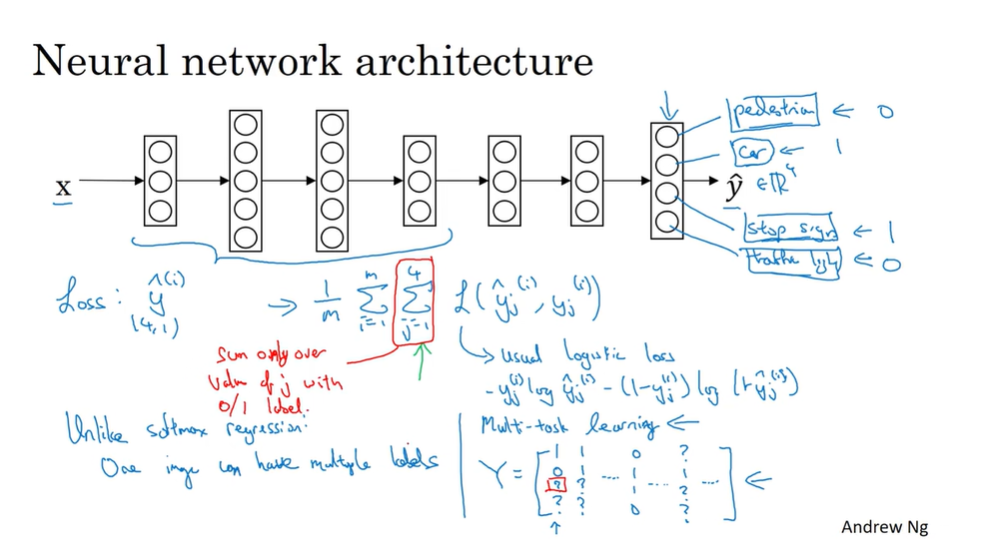
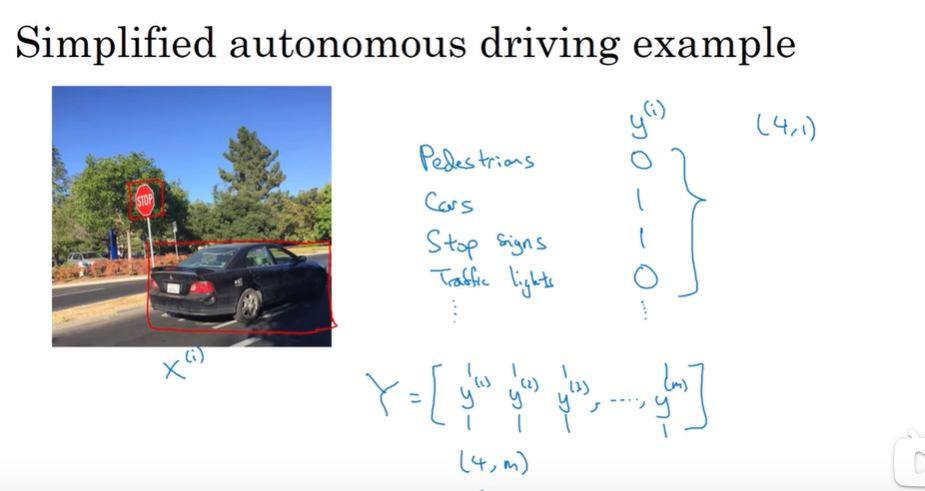 一个X有multiple labels。Y 是(4,m)矩阵.
训练一个nn做4件事比训练4个nn要好:因为神经网络早期特征在识别不同物体时都可以用到(klow level features)
如果是Y有部分标签(有一些标签未知用?代替),那么LOSS对只有标了0,1的标签求和,
一个X有multiple labels。Y 是(4,m)矩阵.
训练一个nn做4件事比训练4个nn要好:因为神经网络早期特征在识别不同物体时都可以用到(klow level features)
如果是Y有部分标签(有一些标签未知用?代替),那么LOSS对只有标了0,1的标签求和,
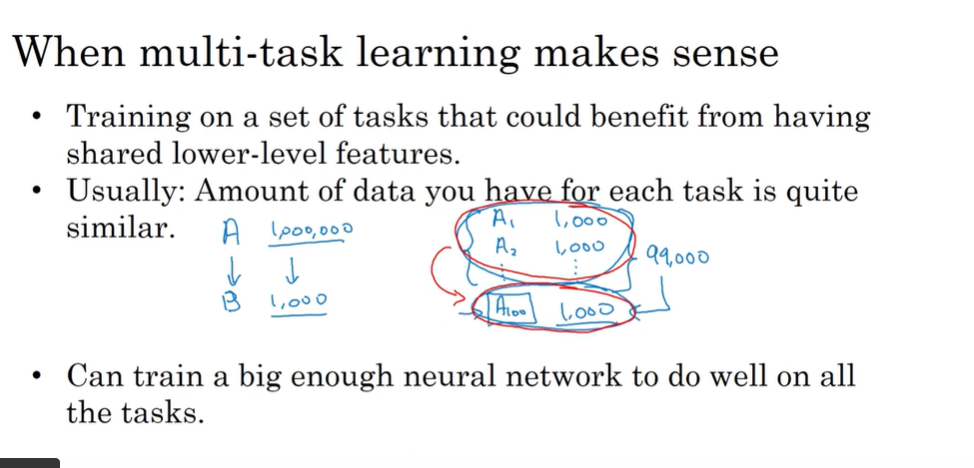
 when make sense:
when make sense:
- 训练的一组任务可共用low level特征
- 其他任务学习可以帮助单任务性能提升。如果想要从多任务学习得到很大性能提升,那么其他任务加起来必须要有比单个任务大得多的数据量,也就是每个人物数据量接近
- nn足够大
端到端学习
Briefly,学习系统,它们需要多个阶段的处理。那么端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它。
 当数据量很大的时候,end-to-end才有很大作用
例子:人脸识别:
当数据量很大的时候,end-to-end才有很大作用
例子:人脸识别:
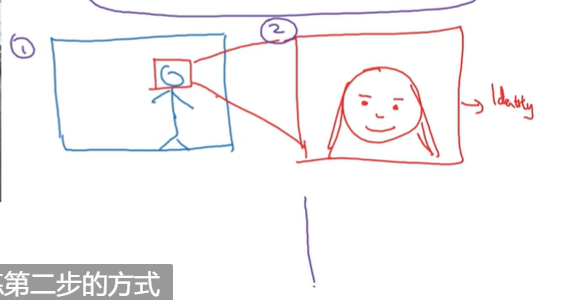 分两步进行,先检测人脸,再给nn识别身份。没有足够多数据进行end-to-end,这样分两步进行比ned-to-end更好
分两步进行,先检测人脸,再给nn识别身份。没有足够多数据进行end-to-end,这样分两步进行比ned-to-end更好
 cons:如果没有大量数据,需要hand-designed结构将人类知识注入进去(但hand-designed也可能效果不好)
cons:如果没有大量数据,需要hand-designed结构将人类知识注入进去(但hand-designed也可能效果不好)
